yoshikingのyoshikingによるyoshikingのためのCTF勉強会、yoshicampがこの季節もまた2日間盛大に開催されました*1。yoshikingと愉快な仲間たちの面子も前回でmitsuくん、今回でkeymoon先生と順調に増えていてなかなかにぎやかです。
今回のyoshicamp 2021 autumnはオフライン開催の機運が高まったので、会津若松の小部屋をお借りして実施されました。ありがとうございます。yoshicampでは会場や宿を貸していただける会社・個人、また合同で勉強してくれるCTFチームを募集しています。
それでは勉強した内容を軽くまとめます。
1日目
相関電力解析攻撃について by yoshiking
まずはyoshikingによるAESの相関電力解析攻撃についての講義でした。相関電力解析攻撃では、鍵kを用いて暗号化処理が行われたときの平文と電力消費量のペアが複数与えられたときに、それらの情報から暗号化に用いられた鍵kを推定します*2。
AESの暗号化の冒頭部分の図を用意しています。ここにあるように、AESではまず、ブロックは1バイトずつに分けられ、最初のラウンド鍵とのxorをとったあとで、SBoxによる非線形な変換を施されます。つまり
c[i] = sbox(m[i] ^ k[0][i])です。相関電力解析攻撃ではこの処理にどれだけCPUの電力が消費されたかを予想します。この処理でどのような値が得られ、それにどのくらいの電力消費が起こるか、というのはラウンド鍵k[i][j]の値によって異なります((当然m[i]によっても変わりますが、今m[i]は既知です))。すなわち、k[i][j]の値を全探索したときにk[i][j]の値によって変わるc[i]の値を用いてこの処理におけるCPUの電力消費量をうまく表せたなら、全探索しているk[i][j] が正しい鍵であったときに予想した電力消費量と実際に得られた電力消費量の動きが似るはずである、すなわち相関が大きくなるはずと考えられます。
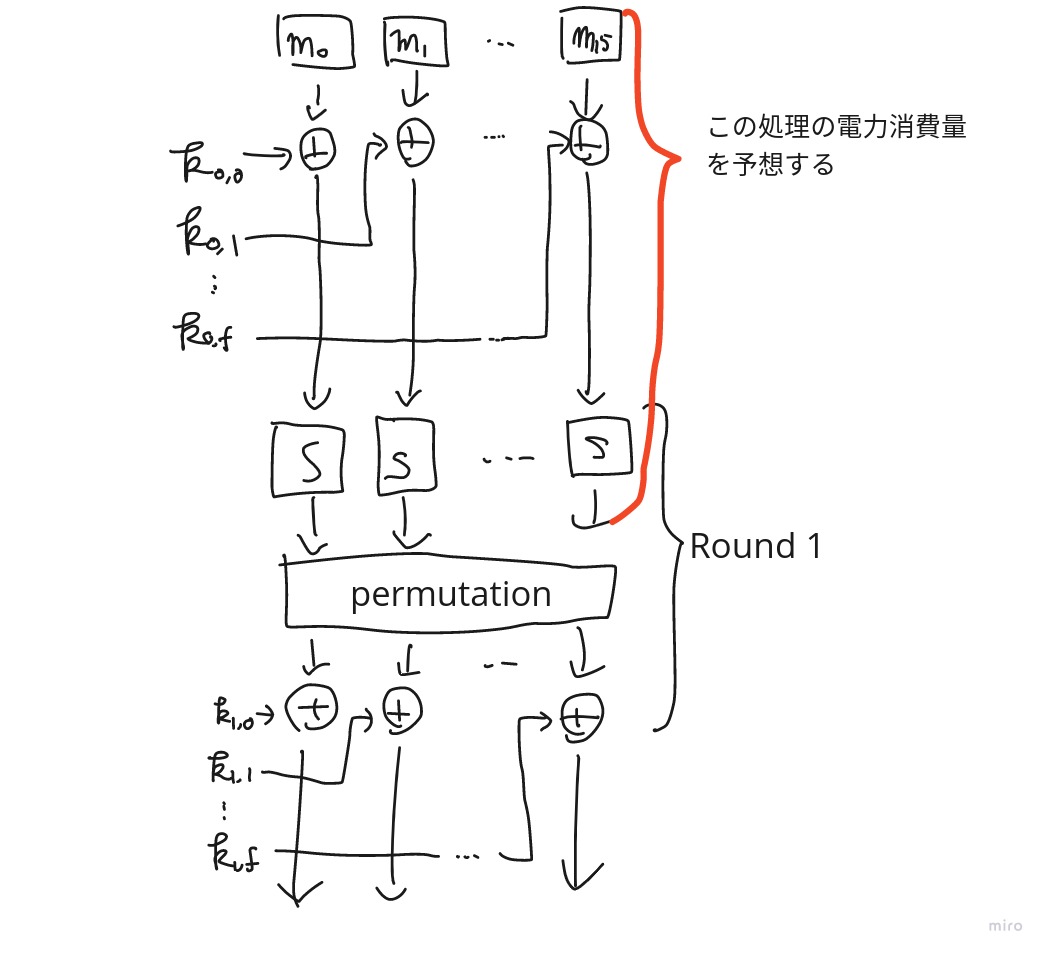
ではc[i]の値によって電力消費量をうまく見積もることができるでしょうか。実は偉大なる先人たちの手によってこれが成し遂げられていて、今回取り上げているようなAESの暗号化冒頭部分の電力消費量についてはc[i]を構成する8bitのうち1になっているbitの数、すなわちハミング重みが電力消費量をうまくモデル化出来ます*3。まるで魔法ですね
やることをまとめます。
- 最初のラウンド鍵
k[0]を構成する16バイトそれぞれの1バイトを256通り全探索する - 各平文
m[j]に対してあるk[0][i]が暗号化に使われたときの消費電力の予想をc[i]のハミング重みとして計算する - 時刻
tを動かしながら各平文を暗号化したときの消費電力量との相関を計算し、高い値が出たときのtとk[0][i]がアタリなのでラウンド鍵k[0]のiバイト目の値がわかる
ということでコードがこちら。これは RHme3 - Qualifiers のTracing the Tracesという問題を解くこーどになっています。文章中では説明していなかったけど、電力の測定ごとに暗号化の開始時刻がずれているので、それを揃えるsynchronizeという処理が入っています。これはyoshikingが提供してくれた関数をkeymoon先生がサッと直してくれたやつです
import ast import math import numpy import random def synchronize(trace, reference, window=[-1,1], max_offset=500): if window[0] == -1: window[0] = max_offset if window[1] == 1: window[1] = len(reference) - max_offset - 1 window_size = window[1] - window[0] reference_window = reference[window[0]:window[1]] sad = [0] * (max_offset*2 + 1) for x in range(0, max_offset*2 + 1): trace_slice = trace[window[0]-max_offset+x:window[1]-max_offset+x] sad[x] = numpy.sum(numpy.abs(reference_window - trace_slice)) sad_idx = numpy.argmin(sad) offset = -max_offset + sad_idx synchronized_trace = trace if offset < 0: synchronized_trace = numpy.concatenate(([0]*abs(offset), synchronized_trace[:-abs(offset)])) elif offset > 0: synchronized_trace = numpy.concatenate((synchronized_trace[abs(offset):], [0]*abs(offset))) return synchronized_trace def h_weight(d): return "{:08b}".format(d).count("1") sbox = [ 0x63, 0x7c, 0x77, 0x7b, 0xf2, 0x6b, 0x6f, 0xc5, 0x30, 0x01, 0x67, 0x2b, 0xfe, 0xd7, 0xab, 0x76, 0xca, 0x82, 0xc9, 0x7d, 0xfa, 0x59, 0x47, 0xf0, 0xad, 0xd4, 0xa2, 0xaf, 0x9c, 0xa4, 0x72, 0xc0, 0xb7, 0xfd, 0x93, 0x26, 0x36, 0x3f, 0xf7, 0xcc, 0x34, 0xa5, 0xe5, 0xf1, 0x71, 0xd8, 0x31, 0x15, 0x04, 0xc7, 0x23, 0xc3, 0x18, 0x96, 0x05, 0x9a, 0x07, 0x12, 0x80, 0xe2, 0xeb, 0x27, 0xb2, 0x75, 0x09, 0x83, 0x2c, 0x1a, 0x1b, 0x6e, 0x5a, 0xa0, 0x52, 0x3b, 0xd6, 0xb3, 0x29, 0xe3, 0x2f, 0x84, 0x53, 0xd1, 0x00, 0xed, 0x20, 0xfc, 0xb1, 0x5b, 0x6a, 0xcb, 0xbe, 0x39, 0x4a, 0x4c, 0x58, 0xcf, 0xd0, 0xef, 0xaa, 0xfb, 0x43, 0x4d, 0x33, 0x85, 0x45, 0xf9, 0x02, 0x7f, 0x50, 0x3c, 0x9f, 0xa8, 0x51, 0xa3, 0x40, 0x8f, 0x92, 0x9d, 0x38, 0xf5, 0xbc, 0xb6, 0xda, 0x21, 0x10, 0xff, 0xf3, 0xd2, 0xcd, 0x0c, 0x13, 0xec, 0x5f, 0x97, 0x44, 0x17, 0xc4, 0xa7, 0x7e, 0x3d, 0x64, 0x5d, 0x19, 0x73, 0x60, 0x81, 0x4f, 0xdc, 0x22, 0x2a, 0x90, 0x88, 0x46, 0xee, 0xb8, 0x14, 0xde, 0x5e, 0x0b, 0xdb, 0xe0, 0x32, 0x3a, 0x0a, 0x49, 0x06, 0x24, 0x5c, 0xc2, 0xd3, 0xac, 0x62, 0x91, 0x95, 0xe4, 0x79, 0xe7, 0xc8, 0x37, 0x6d, 0x8d, 0xd5, 0x4e, 0xa9, 0x6c, 0x56, 0xf4, 0xea, 0x65, 0x7a, 0xae, 0x08, 0xba, 0x78, 0x25, 0x2e, 0x1c, 0xa6, 0xb4, 0xc6, 0xe8, 0xdd, 0x74, 0x1f, 0x4b, 0xbd, 0x8b, 0x8a, 0x70, 0x3e, 0xb5, 0x66, 0x48, 0x03, 0xf6, 0x0e, 0x61, 0x35, 0x57, 0xb9, 0x86, 0xc1, 0x1d, 0x9e, 0xe1, 0xf8, 0x98, 0x11, 0x69, 0xd9, 0x8e, 0x94, 0x9b, 0x1e, 0x87, 0xe9, 0xce, 0x55, 0x28, 0xdf, 0x8c, 0xa1, 0x89, 0x0d, 0xbf, 0xe6, 0x42, 0x68, 0x41, 0x99, 0x2d, 0x0f, 0xb0, 0x54, 0xbb, 0x16, ] print("[+] loading input...") with open("inout.csv") as f: lines = f.read().strip().split("\n") plaintexts = [ [int(ast.literal_eval(d)) % 256 for d in line.split(" ")][:16] for line in lines ] with open("traces.csv") as f: lines = f.read().strip().split("\n") traces = [ numpy.array([ast.literal_eval(d) for d in line.split(" ")]) for line in lines ] print("[+] synchronizing...") ref_trace = traces[0] traces = [ref_trace] + [synchronize(trace, ref_trace) for trace in traces[1:]] trace_len = min([len(t) for t in traces]) for keyidx in range(16): corrs = [] for k in range(256): hs = [] for i in range(len(plaintexts)): x = plaintexts[i][keyidx] y = sbox[x^k] h = h_weight(y) hs.append(h) corr = [] for t in range(trace_len): ds = [trace[t] for trace in traces] corr.append(abs(numpy.corrcoef(hs, ds)[0][1])) corrs.append(corr) print("k = {}, corr = {}".format(k, max(corr))) # debug maxcorr = -1 maxcorrk = -1 maxcorrt = -1 for k in range(256): for t in range(len(corrs[k])): if corrs[k][t] > maxcorr: maxcorr = corrs[k][t] maxcorrk = k maxcorrt = t print("esitmated key: {}".format(maxcorrk)) print(" time: {}".format(maxcorrt))
このプログラムを走らせると、少しずつラウンド鍵を特定してくれます。一緒に time も出力しているけどこれは必要ない情報なので、これを出力しないようにすれば毎回ループしていた部分をmaxで潰せて少し早くなるはずです。
……さて、あとから振り返ってみるとこれまでの内容は全部↓の記事で説明されていました。解いている問題もsynchronizeの中身も一緒だった。なんてこった。しかしこれまで何を言われているのやらという感じだった部分に取り組むことで原理がわかって良かったし、ChipWhisperはよくわからないので頼らなくて済むようになって良かったです。
ところで余談ですがyoshikingの講義資料ではラウンド関数しか表示されていなかったうえにだれもAESの構造を把握していなかったので、ずっとk[0]のXOR気が付かず解けずに苦しんでしました。
Multivariate Coppersmith Methodのお気持ちと実装 by theoremoon
だれもAESを理解していないことがわかったところで、ピザ休憩。そしてその後私によるMultivariate Coppersmith Methodのお気持ちと実装についての講義でした。こちらは以前のyoshicampでのCoppersmith Methodのお気持ちと実装の流れを組んで、如何にこれを多変数に拡張するかということについてお気もちを説明し、実際に実装してみて問題を解いてみようというものです。正直全然準備が出来ておらず、特にまとめてもいない内容をいきなりホワイトボードに書き始めて一人で混乱したりしていた記憶があります。
Coppersmith Methodの多変数への拡張自体はunivariateでの動作がわかっていればさほど難しいものではありません。Howgrave-Grahamの補題が多変数へと拡張できれば、あとはで同じ根を持つ複数の方程式からなる基底についてLLLを用いて係数を小さくし、もとの方程式と同根な整数多項式を得る、という基本的な考え方は同じです。最後に多変数連立方程式を解く、というパートが新しく増えますが、これもグレブナー基底やシルヴェスター行列を使えばできるらしいので、さほど問題にはなりません。……みたいな話を、他の方がもっと詳しく書いてくださることでしょう。
今回の講義(の準備)を通して多変数Coppersmithを実装し、動作原理がさほど複雑でなく、パラメータの調整を自分でやるという選択肢が広がりました。また、時間をおいて復習したことでunivariate polynomialに対してのcoppersmith methodについても解像度があがったような気がします。そして更に、defund/coppersmith が何をしているのかがわかりました。このスクリプトで使われているSequcenceなどのSageの機能、インターネットにはまともな情報が転がってないんですけどdefundはどうやって見つけたんだろう……。
Linux Kernel Exploit入門 by ptr-yudai
怒涛の連続講義で、今度はptr-yudaiによるLinux Kernel Exploit入門でした。毎度のことですがptr-yudaiの講義の完成度は凄まじいものがあります。今回も事前課題+当日資料が配られていて、keymoon先生は講義が始まる前からLinux Kernel Exploitのなんたるかを獲得していたようでした。ところで事前課題を提出していなかったのは私だけらしいです。
当日は事前課題であったLinux Kernelにおけるセキュリティ機構(SMAP, SMEP, KASLR, KPTIなど)についての復習から始まり、脆弱なカーネルモジュールがインストールされているという想定の問題で、セキュリティ機構を有効にしたり無効にしたりしながらExploitを書いていきました。
Linux Kernelのpwnはやったことがなかったのですが、なぜやったことがなかったかといえば何をすればいいかがわからなかったからで、今回の講義で最低限なにをすればいいかがわかったので大分ステップアップしたような感があります。とりあえず cpio コマンドでイメージをまとめてqemuを起動して……という流れを理解し、毎回exploitをそうやってパックしていたら大変なのでwget + base64とかで流し込むという技を得てイテレーションを回せるようになったので、あとはpwnの技術さえなんとかなればKernel Exploitができるようになるはずです。
ptr-yudaiはKernel Exploitはできるようになってしまえばpwnでも最もかんたんな部類と常から言っていますが、それは様々な制約下で、そのとき何ができるかということを知り、どのようなガジェットが存在するか、どのようなガジェットが存在すれば嬉しく、問題を解けるかということを知っている人間の言だということもよくわかりました。Kernel Exploitについての更に詳しい内容はkeymoon先生あたりが書いてくれるはずです。
2日目
2日目は(比較的)若者のkeymoon先生、mitsu先生による講義が控えていました。ということで我々は宿に戻ったあと、夕食や温泉・将棋などを楽しみつつ翌日のための予習をやりました。楽しかったです
実践・最短経路問題 by keymoon
ここに書くことはほとんどなくて、リマスターされた内容がすでにkeymoon先生によって公開されています。ので手短に感想を述べると、このライブラリめちゃくちゃすごいですね。これまで考えていたDPが状態と遷移という概念の導入によってめちゃくちゃスッキリとした形でまとまっていて、フレームワークの強さを感じました。はやくこれを適用可能な問題を見つけてボコボコにしたいです。
猫でもわかる超楕円曲線 by mitsu
全然わからなかった……。全然わからなかったというほどわからなかったということはなく、これまでチラッと見てはなにが書いてあるのかまるでわからなかった超楕円曲線についての論文が、私にとっては一足飛びに、彼らにとっては当然のようにヤコビアンが成す群について論じていたものであったこととか、そのヤコビアンを完結に表現するためのMumford表現が用いられていて、Mumford表現と一対一対応させられる被約因子を代表元に用いているということなどがわかりました。まだこれがどのように群として機能していて、この問題(ヤコビアン上の離散対数問題)の難しさの根拠は何なのかということは全然わかっていませんが、とにかくこれから超楕円曲線について調べていくための足がかりは得られたような気がします。超楕円曲線についてはもっと詳しくなりたいという気持ちが強いので、復習をしたりして理解がました機会にでも増補記事を書くことを画策しています。